业务背景
随着交易量的持续上升,各系统服务面临的压力也越来越大。作为交易链路的重要环节,履约中台提供了运费计算、履约方式寻仓等一系列重要功能,业务对系统吞吐量的要求也越来越高。而特别是履约寻仓可以看作一个流量入口型接口,核心逻辑会依赖履约、商家、商品、设置、库存等多个业务,对外向交易提供功能接口,对内调度各个下游服务获取数据进行聚合,可以算是比较典型的I/O密集型(I/O Bound)特点。在商家逐步全量迁移到新系统之后,交易量日益增长的情况下,使用同步逐个查询各个下游服务的方式已经没办法满足交需求,因此开始考虑将同步加载改为并行加载的可行性。
并行方式
并行从下游获取数据,从IO模型上来讲分为同步模型和异步模型。
同步模型
从各个服务获取数据最常见的是同步调用,如下图所示:
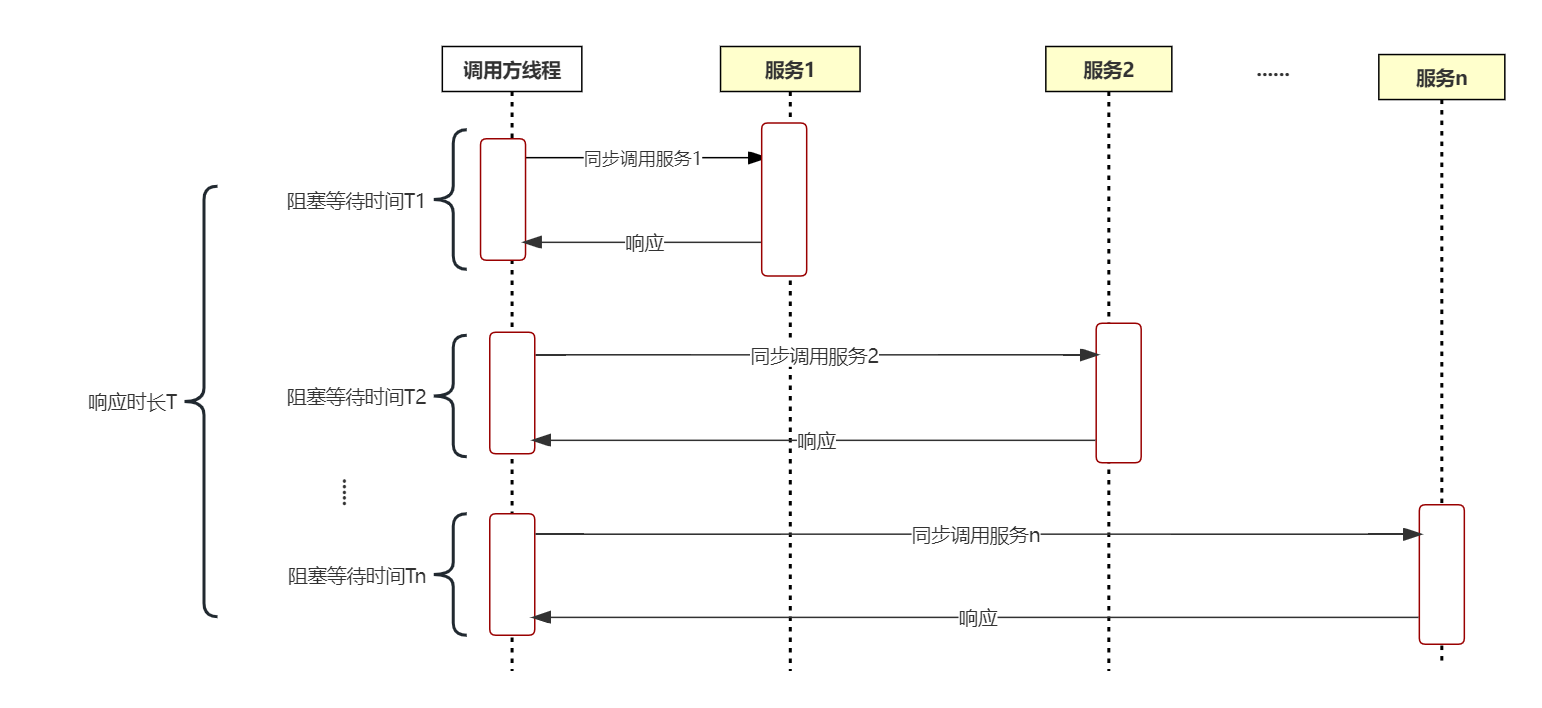
在同步调用的场景下,接口耗时长、性能差,接口响应时长T > T1+T2+T3+……+Tn,这时为了缩短接口的响应时间,一般会使用线程池多线程并行获取数据,但是也存在一定问题,会导致资源利用率比较低:
- CPU资源大量浪费在阻塞等待上,导致CPU资源利用率低。在Java 8之前,一般会通过回调的方式来减少阻塞,但是大量使用回调,又引发臭名昭著的回调地狱问题,导致代码可读性和可维护性大大降低。
- 为了增加并发度,会引入更多额外的线程池,随着CPU调度线程数的增加,会导致更严重的资源争用,宝贵的CPU资源被损耗在上下文切换上,而且线程本身也会占用系统资源,且不能无限增加。
同步模型下,会导致硬件资源无法充分利用,系统吞吐量容易达到瓶颈。
NIO异步模型
我们主要通过以下两种方式来减少线程池的调度开销和阻塞时间:
- 通过RPC NIO异步调用的方式可以降低线程数,从而降低调度(上下文切换)开销,如Dubbo的异步调用可以参考《dubbo调用端异步》一文。
- 通过引入CompletableFuture(下文简称CF)对业务流程进行编排,降低依赖之间的阻塞。本文主要讲述CompletableFuture的使用和原理。
为什么会选择CompletableFuture?
目前业界广泛流行的解决方案,主要包括Future、CompletableFuture注2、RxJava、Reactor。它们的特性对比如下:
|
Future |
CompletableFuture |
RxJava |
Reactor |
| Composable(可组合) |
❌ |
✔️ |
✔️ |
✔️ |
| Asynchronous(异步) |
✔️ |
✔️ |
✔️ |
✔️ |
| Operator fusion(操作融合) |
❌ |
❌ |
✔️ |
✔️ |
| Lazy(延迟执行) |
❌ |
❌ |
✔️ |
✔️ |
| Backpressure(回压) |
❌ |
❌ |
✔️ |
✔️ |
- 可组合:可以将多个依赖操作通过不同的方式进行编排,例如CompletableFuture提供thenCompose、thenCombine等各种then开头的方法,这些方法就是对“可组合”特性的支持。
- 操作融合:将数据流中使用的多个操作符以某种方式结合起来,进而降低开销(时间、内存)。
- 延迟执行:操作不会立即执行,当收到明确指示时操作才会触发。例如Reactor只有当有订阅者订阅时,才会触发操作。
- 回压:某些异步阶段的处理速度跟不上,直接失败会导致大量数据的丢失,对业务来说是不能接受的,这时需要反馈上游生产者降低调用量。
RxJava与Reactor显然更加强大,它们提供了更多的函数调用方式,支持更多特性,但同时也带来了更大的学习成本。而我们本次整合最需要的特性就是“异步”、“可组合”,综合考虑后,我们选择了学习成本相对较低的CompletableFuture。
